Performing over-the-air updates of devices in the field can be a tricky business. Reliability and recovery is of course key, but even getting the right bits to the right storage sectors can be a challenge. Recently I’ve been working on a project which called for the design of a new pathway to update some small microcontrollers which were decidedly inconvenient.
There are many pieces to a project like this; a bootloader to perform the actual updating, a robust communication protocol, recovery pathways, a file transfer mechanism, and more. What made these micros particularly inconvenient was that they weren’t network-connected themselves, but required a hop through another intermediate controller, which itself was also not connected to the network. Predictably, the otherwise simple “file transfer” step quickly ballooned out into a complex onion of tasks to complete before the rest of the project could continue. As they say, it’s micros all the way down.
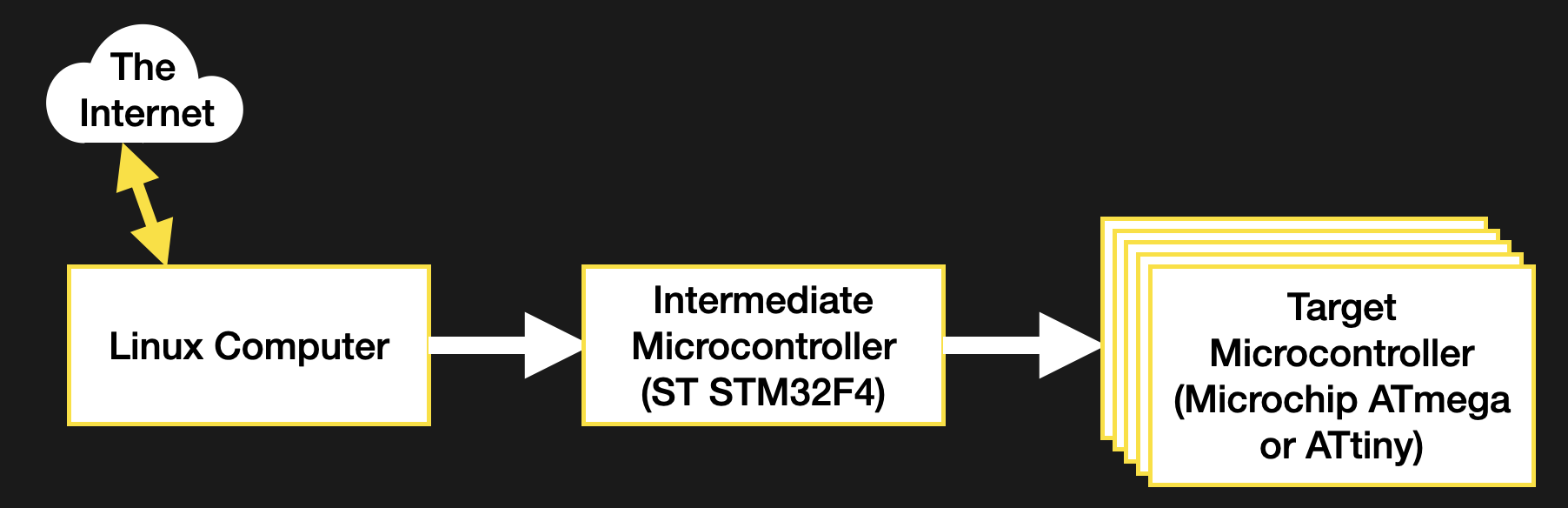
The system in question isn’t particularly exotic. The relevant portion is composed of a network connected Linux computer wired to a large microcontroller, wired to a variety of smaller controllers to manage various tasks. I needed to be able to update this fan-out of smaller controllers. To save complexity I decided I would have the intermediate microcontroller responsible for the update process of its children. But this presented a new problem; how do we get the firmware images into the intermediate controller?
The micro in questions is fairly powerful, with a hefty dollop of external flash (formatted with littleFS, naturally) but getting the files into that flash would force me to develop a filesystem interface for the Linux computer. Not an issue, but a large piece of work and a significant diversion from the task at hand: bootloading those darn controllers! Then someone suggested an excellent way to simplify the process down to nearly nothing; what if I bundled the target firmware images with the firmware for the intermediate controller itself? Then flashing the intermediate would also transfer the payload firmwares for free! Definitely an expeditious strategy, but how to do it? This turned out to be a more interesting problem what I had anticipated. Let’s see how to get the images into the firmware.
Options for Images
I explored four methods for performing the firmware image bundling: compiling the payload firmware as a header, linking it in as an object file or modifying the compiled output to inject it, and directly editing the final binary. Among other differences, each of these strategies lends itself to usage at different points in the development process. Linking makes sense only when compiling the firmware, linker tricks work just after compilation, and binary editing can happen at any point after the binary is completed.
As this was a component of a larger stability-focused project, tracking the exact version of each separate firmware image was extremely important for bug-hunting and traceability. Ideally, each image would be somewhat decoupled, so they can be individually changed without recompiling everything. Adding further complexity to the problem was a need for three images — each controller runs a separate application — and two toolchains, as the intermediate and target microcontrollers were of different architectures. Though one of the four options was the best fit for my needs, all four are worth discussing.
The Classic: A Header File
There’s no trick to this method, it’s exactly as simple as it seems. You use a tool to effectively “print” the payload binary as a series of individual byte constants, then dump them into a source file as an array and compile away. Access is a snap, it’s just an array of fixed size! You can even use a sizeof() to figure out how much data is available.
There are a bunch of tools which facilitate this workflow, the most surprising being that paragon of utilities GIMP, which can export to C source directly. A more CLI friendly option (and one which will come up again) is xxd. xxd is nominally used for converting between raw binary and a variety of hex file formats, but can also be configured to export a C source file directly with the -i flag. The output should look pretty familiar if you’ve seen a constant C array before:
borgel$ xxd -i somefile.bin
unsigned char somefile_bin[] = {
0x22, 0x22, 0x22, 0x47, 0x75, 0x69, 0x64, 0x65, 0x20, 0x74, 0x68, 0x65,
...
0x69, 0x6f, 0x6e, 0x22, 0x5d, 0x0a, 0x29, 0x0a
};
unsigned int somefile_bin_len = 10568;
Pretty handy, right? Direct that output to a source file and compile away. Unfortunately this wasn’t a good fit my my application. I couldn’t guarantee that the payload firmware would always be available at compile time, and even if it was it would be somewhat more difficult to trace the exact version it had been built from without reading it from the final binary itself or creating a separate version file. So a C header was out.
Slick Linker Magic
For a compiled programming language like C, the compiler probably produces intermediate object files. You’ve seen them as the .o‘s hanging around in your directory tree. These contain compiled segments of the program in question, as well as metadata about where that code will eventually land in the final executable along with other information used by a linker or debugger. Well, it turns out that anything can be turned into an object file by wrapping it in the right bytes, including another binary.
With gcc and gcc-compatible tools this object file wrapping can be done with ld (the linker) itself with the -r and -b flags. -r asks ld to produce an object file as its output, and -b lets us tell it the input format (in this case binary). Note on some platforms -b seems to be deprecated and may not be necessary. The full command looks something like this:
borgel$ ld -r -b binary somefile.bin -o somefile.o
That’s essentially it. This somefile.o can be linked in with the rest of the object files to comprise a complete program.
Using the embedded binary with the running executable is more complex than reading a constant array, but only just. The linker automatically adds some magic symbols to the object file describing the start address, end address, and size of the payload (in this case a binary). On the development machine these can be verified in a few ways, the most ergonomic being nm (for listing symbols in an object file) and objdump (the object file dumper) – both part of a normal GNU binutils install. Each is very powerful but let’s use objdump as our sample:
borgel$ objdump -x somefile.o somefile.o: file format ELF32-arm-little Sections: Idx Name Size Address Type 0 00000000 0000000000000000 1 .data 00002948 0000000000000000 DATA 2 .symtab 00000050 0000000000000000 3 .strtab 0000004f 0000000000000000 4 .shstrtab 00000021 0000000000000000 SYMBOL TABLE: 00000000 *UND* 00000000 00000000 l d .data 00000000 .data 00000000 .data 00000000 _binary_somefile_bin_start 00002948 .data 00000000 _binary_somefile_bin_end 00002948 *ABS* 00000000 _binary_somefile_bin_size
We’re not really interested in most of this, though it’s interesting to poke around at compiled binaries to see what they contain (for that, also try the strings tool). For our purposes we want the three __binary_somefile_bin_* symbols. Note their absence in the ld one-liner above, they are automatically named and placed by the linker. The column of numbers on the left of the SYMBOL TABLE section are the offsets in the object file where each symbol is located, in hex. We can get the size of our binary (in this case with a simple ls)
borgel$ ls -l somefile.bin somefile.bin -rw-r--r--@ 1 borgel staff 10568 Aug 15 14:22 somefile.bin
to see that the symbols _binary_somefile_bin_size and _binary_somefile_bin_end are correctly placed after a block the same size as our input file (10568 = 0x2948). To access these symbols in C, we add them as extern to any file that needs them, like so:
extern const char _binary_somefile_bin_start; extern const char _binary_somefile_bin_end; extern const int _binary_somefile_bin_size;
Then they can be referenced in code like any variable. Remember they’re intended as pointers to the data on disk. That is, their address is meaningful, and the data stored at that location is the data on disk at that address.
This method works great, and feels better encapsulated than directly converting everything to a source file. But it suffers from similar problems to the previous approach; that tracking the provenance of the resulting binary can be complex without embedding additional symbols.
In my case, the bigger problem was that in order to work with the object files you must have tooling that supports that particular processor architecture. Not a problem when bundling software for a desktop, but in my case it meant I needed a copy of the arm-none-eabi-gcc tooling on hand at a point in the build process where it wasn’t already present. This was possible to fix, but there were better options.
But Wait, There’s More?
Did we just cover all of the possible ways to build a binary? Hardly! But these two options are both best suited for compile time and cover the most common needs for embedding binaries. Where are you most likely to encounter them in these pages? Probably when embedding images in microcontroller firmware. Compiling a bitmap down to a header is perhaps the easiest way to go from an image on a desktop to a display attached to a micro.
If all this talk of object files is getting you thinking of more ways to explore the compiler’s leavings, check out [Sven Gregori]’s excellent post on creating plugin systems with shared libraries; a closely related topic. And if the thought of working with binaries is filling your mind with possibilities, [Al Williams] has your number as he works through the process of creating binary files using xxd and other common Linux tools.